Optimizing AWS Elastic Kubernetes Service (EKS)
As you develop environments, infrastructure, and orchestration platforms (like k8s), you'll begin to notice that there are several directions to go in. There's a joke that goes something like "line up 100 engineers, ask them the same question, get 90 different answers" and this is what makes engineering so fun.
On the flipside, it's also what makes figuring out a specific solution and best path forward so daunting.
In this blog post, you'll learn a clear way to think about optimization for EKS that has been implemented countless times and has been tested vigorously in production.
Architecture and Design
The first thing you'll need to think about is the architecture and design. As mentioned in the opening of this blog post, there are hundreds or thousands of way to solve a particular problem, and because of that, you need to design the solution to your needs.
An EKS cluster that that's running for a 50 person website company is going to look very different from 500 EKS clusters running for a huge organization. The best way to combat this in the beginning, because you don't know what you don't know, so you'll have to sort of "guess" from the start, is to implement Kubernetes with best practices.
- Minimum of 3 Worker Nodes (the Control Planes are abstracted from you with EKS).
- Logging turned on for everything that's available within EKS (like audit logging).
- Multi-AZ (across multiple data centers)
The above is just for performance to get the cluster up and running, but you'll learn more about the overall specifications (security, performance, optimization, automation, etc.) throughout this blog post.
Once the cluster is up and running, test, test, and test some more. There are a ton of tools that you can use, from Chaos Engineering tools to Performance Benchmarking tools to have virtual/fake users target an application to use that you've deployed. You can then see how the environment will hold up. Did the Pods run out of resources? Did the cluster properly scale?
You'll get a lot out of understanding how the basics of the cluster will work with Performance Benchmarking and Chaos Engineering tools.
The last piece when designing is to understand how you want EKS to run. Currently, there are four methods:
- Standard EKS with EC2 instances as Worker Nodes.
- EKS with Fargate profiles (Serverless k8s)
- EKS Hybrid Mode (run EKS Worker Nodes on-prem)
- EKS Auto Mode (Control Plane and Worker Nodes are abstracted away from you).
The best way to answer this question is to dive in, test the ones that you know you'll need (for example, if you're not running on-prem, you don't need to test EKS Hybrid Mode) and see what best suits you.
For example - EKS Auto Mode is great. It abstracts away every piece of infrastructure/systems management along with the performance optimization and out-of-the-box security features that are implemented. However, with that abstraction, you have way less control over the environment. That may not work for you, and that's okay, but at least you tested it out to confirm.
Day Zero, One, and Two
The next step after architecting, designing, and vigorously testing what you want to deploy is:
- Day Zero: Deployments, getting the environment up and running, and more architecture/design.
- Day One: Monitoring, observability, and deploying apps.
- Day Two: Upgrades, backup, maintenance, security.
Day Zero is all about getting the environment up and running. Your best friends here will be Infrastructure-as-Code and CICD. In terms of which solutions you go with, it's really a matter of what you're comfortable with as they're all doing the same thing, but in a different way.
For example, Terraform is conceptually doing the same thing that Cloud Formation is, but you may want a solution that's a bit easier to digest, write, and is agnostic, so you go with Terraform. The same rules apply for CICD. You can have multiple pipelines in the same repository in GitHub Actions, but in Gitlab, you'll have multiple stages within the same pipeline to deploy what's in the repository. They're both doing the same thing, but in a different way.
Day One is getting the application stacks deployed after Day Zero of getting the environment deployed along with monitoring and observability. As far as application deployments, GitOps is the way to go in today's world and the tool that most people are going with is ArgoCD. This allows you to have your source control repo be the source of truth. ArgoCD looks at the source control repo and deploys what is there automatically.
As far as monitoring and observability, you have two options:
- Homegrown
- Enterprise
Homegrown is typically an open-source stack like Grafana/Loki/Tempo/Prometheus. Enterprise is something like Datadog. There is no right or wrong answer here, but the best thing to remember is that with an open-source stack, someone has to maintain it. With an enterprise stack, it's SaaS based tooling so you aren't on the hook for managing and maintaining it like another application.
Day Two is all about maintenance, upgrades, backups, and security. As far as security, you'll learn about that in an upcoming section. As far as maintenance and upgrades, blue/green deployments will be the direction that you want to go in. Instead of upgrading a cluster, you can create a new cluster, register it with ArgoCD, have all of your apps deployed, cut everything over from a networking perspective, and destroy the old cluster. Because random issues due end up occurring during upgrades and it ends up being a hassle, many organizations are going the blue/green route.
As far as backups - no one is really backing up EKS itself. It's usually the persistent data resources (like Volumes) and Etcd (the k8s database) that need proper backups.
Performance Optimization
You may hear a lot of what's in this section called resource optimization or cost optimization, but the category as a whole is performance optimization. You can't properly save costs if you don't know how an environment is optimized properly from a performance perspective, and you can't understand the performance of an environment as a whole without knowing the performance needs of an application stack.
For performance optimization, you need to think about resource optimization, and you'll optimize two sets:
- The cluster itself
- The workloads running within the cluster
For resource optimization with the cluster, Karpenteris a no-brainer. It's faster than cluster autoscaler in terms of scaling nodes down and it has a "scale to zero" implementation where if workloads aren't being used. You can also implement a NodePool via the Karpenter CRD to specify what instances types you want to be available to your cluster.
Optimizting and scaling workloads running in a cluster will come down to:
- KEDA: Event-driven autoscaling. For example, you can scale based on an event that comes in via a Service Bus.
- Horizontal Pod Autoscaling (HPA): Add more replicas if resources hit a certain percentage of usage (for example, 75% for CPU usage).
- Vertical Pod Autoscaling (VPA): Add more CPU/memory to existing Pods. You'll typically see HPA used more.
- Requests/Limits/Quotas: Ensure that Pods can only use a certain amount of CPU/memory. For example, if you have a memory leak in your app, you don't want the Pod to keep getting more and more memory from Worker Nodes as it would be a waste.
Another cool tool in AWS is AWS Trusted Advisor, which will help you understand the proper performance and cost optimization necessary to ensure the environment is running as expected.
Testing
As mentioned previously, you can use a Performance Benchmarking tool to test and ensure that the scalability you configure is what works best within your environment.
Cost Optimization
All good cost optimization comes from performance optimization. Without understanding how an app and app stack should perform, Cost Optimization isn’t beneficial. Please see recommendations in the Performance Optimization section.
Aside from ensuring proper performance optimization, there are three things you can think about:
- Enabling proper billing alerts and cost analyses via the Billing service in AWS.
- Reserved instances (pay for resources upfront).
- Spot instances (instances that will get taken away and new ones come up in its place, so ephemeral instances).
Number 3, spot instances, are actually the way to go for many organizations that have ensured proper scalability. If you, for example, have 3 Worker Nodes running as spot instances and one goes away, a new one will come up in its place and the Pods running on that instance will be automatically scheduled on another Worker Node in the pool, so it's a great way to save money.
Security
The last piece of the puzzle if security, but it certainly shouldn't be something you forget about. In a production environment, security implementation usually comes last because you can't secure what doesn't already exists, so the previous steps you learned about have to come prior.
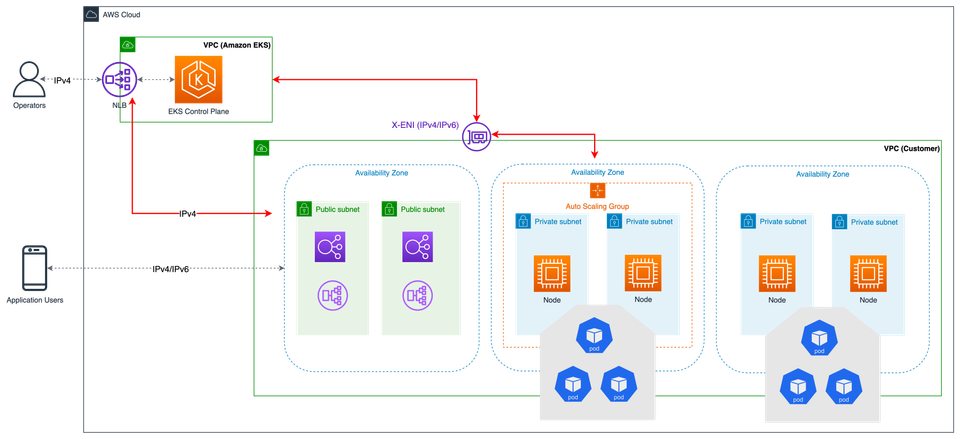
However, there is ONE thing you'll have to architect and design from the start - a private Control Plane.
Private Clusters
Control Planes on Managed Kubernetes Services come, by default, as public-facing. This is an awful practice as that means the k8s cluster can be reached from anywhere and that's a huge vulnerability.
As a best practice from a security perspective, which falls under the 4 C’s Of Cloud Native, OWASP k8s Top 10, and many other frameworks, the Kubernetes Control Plane should be private. This will ensure that the Control Plane is not public on the internet. This change will require a “VPN-style” configuration as you won’t be able to reach the Control Plane from anywhere.
The cluster itself can have public subnets for public-facing apps (for example, if an app is running behind a k8s Service and it’s public-facing), but it should have private subnets for the Control Plane itself.
Tenancy Challenges
As you're deploying clusters and workloads, you'll hear about multi-tenancy and single tenancy.
Multi-Tenancy
- One cluster with multiple people accessing it.
- More than one engineer is working on it.
- More than one application/stack is deployed on the cluster.
Single Tenancy:
- Cluster per person.
- One engineer is accessing the cluster.
- One application/stack is deployed on the cluster.
Typically, organizations go with a multi-tenancy configuration because of the overall management and cost of single tenancy
When implementing a multi-tenancy environment, here are the key requirements for security:
- Proper isolation
- Namespaces
- Network Policies
- Policy Enforcement
- Proper RBAC
Cluster Security and Isolation
- Policy Enforcement
- Open Policy Agent (OPA)
- Secrets Management
- Kubernetes Secrets
- HashiCorp Vault
- AWS Secrets Manager
- Pod Security Standards
- Use an
AdmissionConfiguration
- Use an
Workload Security And Isolation
- SecurityContexts within each Kubernetes Manifest
- Pod security
- Cilium with eBBF
- Network Policies (possible to use with Cilium or AWS CNI)
- Cilium with eBBF
- Service security
- Service Mesh
- Traefik or Istio
- Service Mesh
Scanning Tools
Scanning your environment to check for CVEs is key to properly maintaining a balance of what you can control and what you can't control in security. Security is all about mitigating as many risks as possible, not stopping all risks, and scanning tools help with that.
- Kubescape (open-source version or paid)
- Scans container images
- Scans manifests
- Scans clusters
- Docker scout
- Container image scanning
- Checkov
- Container image scanning
- SCA scanning
- k8s manifest scan
- Pentesting tools
- Tools like OWASP ZAP or Burpe Suite allow you to pentest your web apps to ensure that they're as secure as you expect them to be.

Comments ()