Managing an Agents Uptime (Reliability Engineering for Agents)
"treat 'em like cattle, not pets".
This was, and continues to be, how many look at Kubernetes Pods and microservice-based architecture. It makes a lot of sense for objects like Pods because if one goes down, a new one comes up in its place with the same configurations thanks to reconciliation loops (Controller).
Now the question becomes: can Agents be treated that way too?
This blog post covers key aspects of managing Agent time and the ability to rehydrate an Agent to resume where it left off.
Agents Are Being Deployed Like Pets
Agents, in the grand scheme of things, are still new. They're new for people that are implementing them in production, creating patterns around them, and ensuring they work as expected. Like all new technology stacks that come up, when something is new, it's human nature to "protect it" as much as possible. That means treating Agents like a rare animal that must be looked after and healthy at all times.
Luckily, that's no longer the case. You can treat your Agents like you would your Pods in the k8s world. If one goes down, who cares? A new one comes up and you may have various replicas already in place.
There are several components that when put together, ensure that whether an Agent goes down, stop mid-way through a task, or goes into an unhealthy state, a new Agent can replace it and pick up where it left off.
Memory
Long and short-term memory allows an Agent to completely shut down and then pick up where it left off. If you turn this into context that you may already be familiar with; you know how if you stop runing claude or codex and you'll get a message saying something along the lines of "to resume, run claude --resume xxxx"? That's due to the context being saved. Now, this of course depends on the client you're using, but there's always a database on the backend storing persistent information
Within kagent, memory persists in Postgres (kagent uses Postgre with pgvector) after the session ends. Entries expire by TTL, so you have full control of how long the persisted memory sticks around.
memory:
modelConfig: embedding-model # references the embedding ModelConfig above
ttlDays: 15 # memories expire after 15 days (default)kagent stores long-term memory scoped by user and agent. Those memories are embedded as semantic vectors, so the Agent can retrieve related past context by meaning, not exact wording. For example, if a user repeatedly deploys demos to aksenvironment01, kagent can remember that preference for that user when the same agent handles future deployment questions and can ask the user the question "hey, I see you're deploying a demo - do you want to deploy to aksenvironment01".
agent_name: k8s-agent
user_id: michael
content: User usually deploys demos to namespace abac-demo.
embedding: [768 numeric values representing semantic meaning of content]
expires_at: ...Context/State
When thinking of context/state and memory, you can break it down like the following:
- Memory = persisted past knowledge outside of current convo.
- Context = Info currently supplied to the Agent for this turn.
That's why you'll see Claude or Codex save sessions that you can resume. That's coming from memory, but once you're in the session, that's now the context.
context:
compaction:
compactionInterval: 5
overlapSize: 2
tokenThreshold: 50000
eventRetentionSize: 10In kagent specifically:
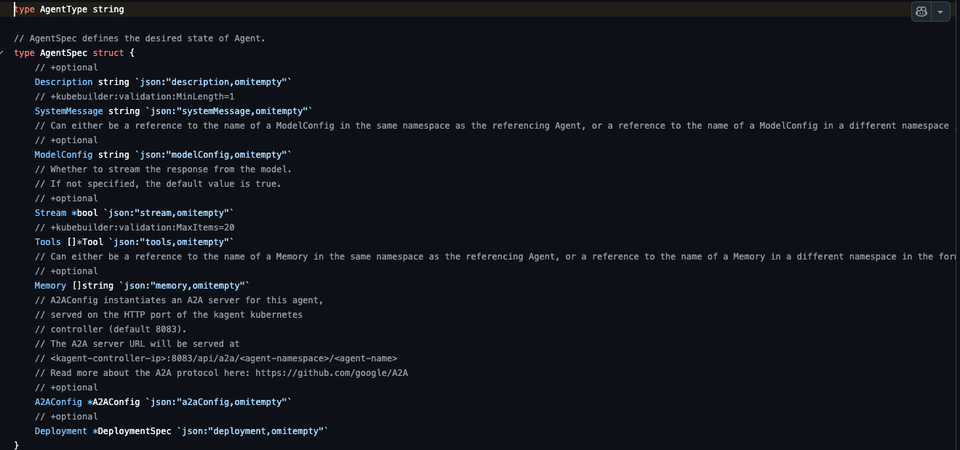
spec.declarative.memoryenables long-term memory tools and vector retrieval.spec.declarative.contextis separate; it manages current session context, like event compaction/compression.prefetch_memorycan inject retrieved memories into model request as past-conversation context.
Reconcilation
If you've used Kubernetes before, you might've heard something along the lines of "k8s has self-healing". That self-healing isn't magic, it actually comes from a Kubernetes Controller. For example, if I have a Deployment with three replicas, but only two exist, the ReplicaSet Controller will do what it can to up the replica count by one to ensure that the current state is the desired state defined by the user. This is possible by an interval of sorts with the reconcilation loop that constantly checks to ensure that the current state is the desired state.
In kagent, there's an AgentController that watches the Agent object and ensures that the current state is the desired state. If it's not, it will attempt to repair the Agent. This works much like any other k8s object that has a Controller. The AgentController owns the generated resources, which are Deployment, Service, Secret, and ServiceAccount (/kagent/go/core/internal/controller). The Agents Pod, however, is still managed by the ReplicaSet Controller.
All of that to say that your Agents can be managed and handled in the same way as any other k8s object, which gives you built-in self-healing.
Checkpoints and Snapshots
In Agentic solutions or even agent sandboxes, you will see the concept of checkpoints and/or snapshots. You can think of a snapshot as a point-in-time backup for your Agent. Checkpoints are like a "time-travel" mechanism through conversations that allows an Agent to pause, resume, and save the state after every execution.
A great example of checkpoints is with langgraphs checkpointer pattern. It allows for a few patterns: MemorySaver, PostgresSaver, and RedisSaver.
With BYO, you can implement this exact pattern.
kagent sends an A2A request to the langgraph agent and the LangGraphAgentExecutor creates a langgraph config like the following:
{
"configurable": {
"thread_id": "<kagent-session-id>",
"app_name": "currency-agent",
}
}The graph runs and the KAgentCheckpointer saves the checkpoint to the kagent Controller.
POST /api/langgraph/checkpoints
X-User-ID: michael
user_id: michael
thread_id: <kagent-session-id>
checkpoint_ns: ""
checkpoint_id: <langgraph-checkpoint-id>
checkpoint: <serialized LangGraph state>
metadata: <serialized metadata>The Agent can then resume with prior state.
Registry
If your registry cannot only save/store Agent Skills, prompts, and MCP tools, but also has the ability to deploy Agents, that means if an Agent goes down, it can get re-deployed in an extremely short period of time, as long as there is automation in place to re-deploy or alerting is set up on said Agent.
The goal here is:
- You have a collection of your Agent Skills, prompts, and MCP tools that an Agent needs.
- You know the Agent that these components need to be deployed to.
- You deploy the Agents with these components.
It's like a package for Agents to run as expected.
Observability
The last step is general observability; logs, traces, and metrics
Much like any other workload that runs on servers/systems, data is exposed. In the world of AI, this data is typically exposed 99% of the time from your AI Gateway.
The three questions that always come up are:
- How can I look at end-to-end traces from my Agent to its destination (an LLM, MCP Server, or another Agent).
- Can I secure that traffic.
- What is it going to cost me?
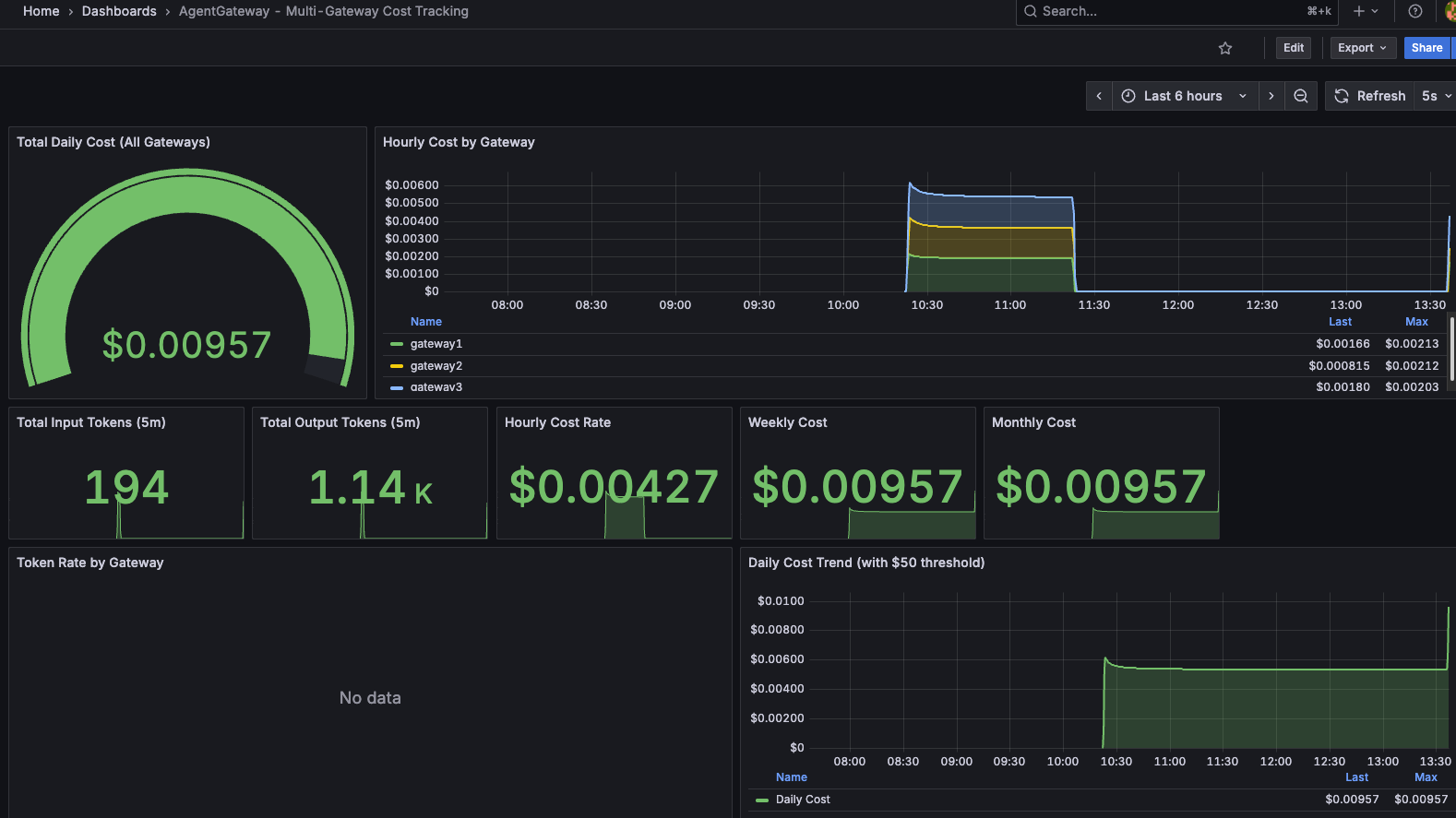
In the world of reliability engineering, it often comes down to how the Agent performs and cost optimization. Folks often think cost optimization isn't part of reliability engineering, but think about it; if you have an app running on a server and you realize its taking up a massive amount of RAM due to a memory leak, chances are you found that out because servers kept getting spun up or RAM kept getting vertically added to an existing server skyrocketing costs.
From a pure performance perspective, it comes down to what traces and metrics you have readily available to you, and the only way you can retrieve that information effectively is by having a "line of communication" or a "tunnel" sitting between your Agent and its desination. That "tunnel" is your gateway.
Wrap-Up Checks With Evals
With all of the above, it's also useful to think about the following:
- Idempotent: If the Agent crashes mid-tool call, are there any side effects? Did it half-happen?
- Authentication: If an Agent is mid-flight and it crashes, do you have a "zombie token" floating around? That's of course where short-lived tokens can help, but they aren't always the chosen path.
- Point-in-time-state: If an Agent crashes mid-flight, you may have a snapshot of the Agent, but do you have a snapshot of the Agent based on what it was doing at the exact moment of the crash?
Now, this list may look like semantics (pun intended), but it's all technically in the realm of possibility. It's something that's great to test and confirm with agentic evaluation frameworks like agent evals. You can ensure that what the Agent is doing before and after a crash is what you expect.


Comments ()