Protecting Environments Implementing AI With Prompt Guards
You decide to start using AI and AI Agents within your environment. You use a chat/terminal feature, ask the Agent to do a few things, and get up to grab a cup of coffee. By the time you return, the Agent has deleted a ton of databases and your entire system is down.
No, this isn't a myth (it's happened) and yes, there is a way to protect against it.
In this blog post, you'll learn how to use prompt guards to protect against malicious activity.
Prerequisites
To follow along with this blog post from a hands-on perspective, you'll want to have the following:
- A Kubernetes cluster (doesn't matter where it's running)
- An Anthropic API key. If you don't use Anthropic/Claude Models, you can use whatever Provider you'd like based on what's supported on agentgateway. You can find the full list of supported providers here.
- OSS kgateway (the control plane) with agentgateway (the dataplane/proxy) installed. You can find the installation for how to do that here.
Why Prompt Guards
There are several attack vectors in the AI space, but the one that you tend to hear about the most is prompt injection. Prompt injection is the act of putting malicious text into a prompt that makes the AI Agent do something that it shouldn't do.
An example is something like "delete every Kubernetes cluster in this AWS account" (well, at least it's an assumption that you don't want to do that).
Prompts are at the forefront of anything Agentic related, and that means it's one of the largest paths to an attack. Because of that, ensuring that guardrails are set up for malicious attacks to not occur makes sense to implement.
On the other side, it may not even be a malicious attacker that you want to protect against. You just may not want an Agent to perform a particular action. Maybe an Agent is being used to manage HR data, but you don't want the Agent to be able to access something like social security numbers, so you'd put guardrails in place to protect against that.
This is where prompt guards, a feature used in agentgateway comes into play. In the following sections, you'll learn how to configure a gateway and implement a prompt guard.
Setting Up A Gateway
With the understanding of why protecting against certain prompts is important, let's create a gateway that we'll use to send a request to an LLM.
- Export your LLM provider API key.
# Change based on what LLM provider you use
export ANTHROPIC_API_KEY=- Create a Kubernetes Secret with the LLM API KEY.
kubectl apply -f- <<EOF
apiVersion: v1
kind: Secret
metadata:
name: anthropic-secret
namespace: kgateway-system
labels:
app: agentgateway
type: Opaque
stringData:
# Change based on what LLM provider you use
Authorization: $ANTHROPIC_API_KEY
EOF- Create a Gateway with agentgateway as the dataplane/proxy.
kubectl apply -f- <<EOF
kind: Gateway
apiVersion: gateway.networking.k8s.io/v1
metadata:
name: agentgateway
namespace: kgateway-system
labels:
app: agentgateway
spec:
gatewayClassName: agentgateway
listeners:
- protocol: HTTP
port: 8080
name: http
allowedRoutes:
namespaces:
from: All
EOF- Create a backend that tells kgateway (the control plane) what to route to (in this case, an LLM).
kubectl apply -f- <<EOF
apiVersion: gateway.kgateway.dev/v1alpha1
kind: AgentgatewayBackend
metadata:
labels:
app: agentgateway
name: anthropic
namespace: kgateway-system
spec:
ai:
# CHANGE based on what LLM provider you use
provider:
anthropic:
model: "claude-3-5-haiku-latest"
policies:
auth:
secretRef:
name: anthropic-secret
EOF- Create a route to the LLM so you can reach particular paths with a
curlor any other client
kubectl apply -f- <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: claude
namespace: kgateway-system
labels:
app: agentgateway
spec:
parentRefs:
- name: agentgateway
namespace: kgateway-system
rules:
- matches:
- path:
type: PathPrefix
value: /anthropic
filters:
- type: URLRewrite
urlRewrite:
path:
type: ReplaceFullPath
replaceFullPath: /v1/chat/completions
backendRefs:
- name: anthropic
namespace: kgateway-system
group: gateway.kgateway.dev
kind: AgentgatewayBackend
EOF- Capture the ALB IP address.
If you don't have a public ALB IP, you'll use localhost in step 7 instead of the INGRESS_GW_ADDRESS variable (so you can skip this step if you're port-forwarding the gateway Service).
export INGRESS_GW_ADDRESS=$(kubectl get svc -n kgateway-system agentgateway -o jsonpath="{.status.loadBalancer.ingress[0]['hostname','ip']}")
echo $INGRESS_GW_ADDRESS- Test the LLM connectivity.
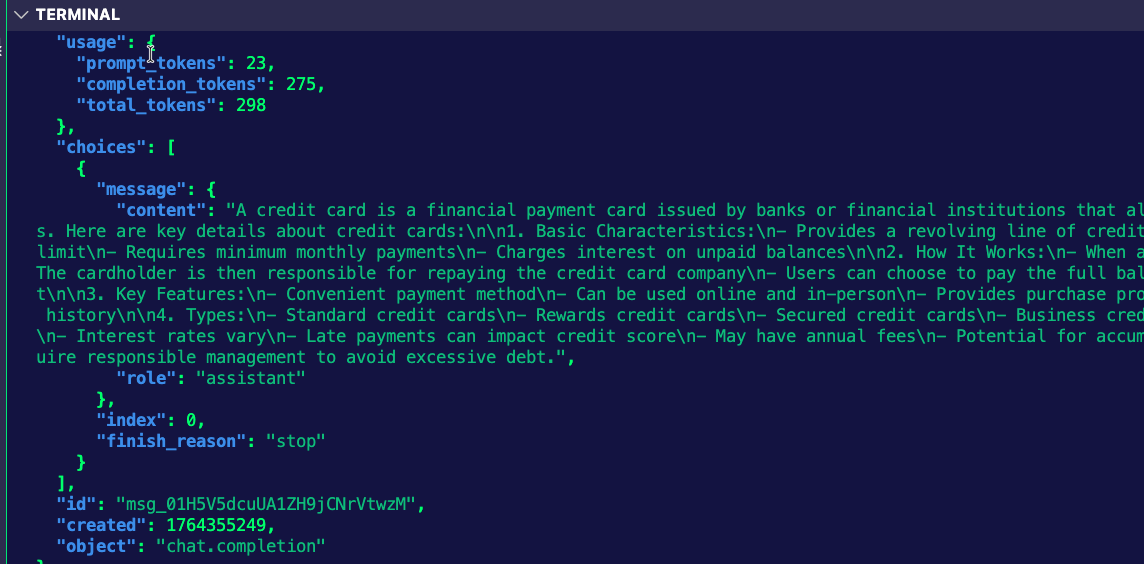
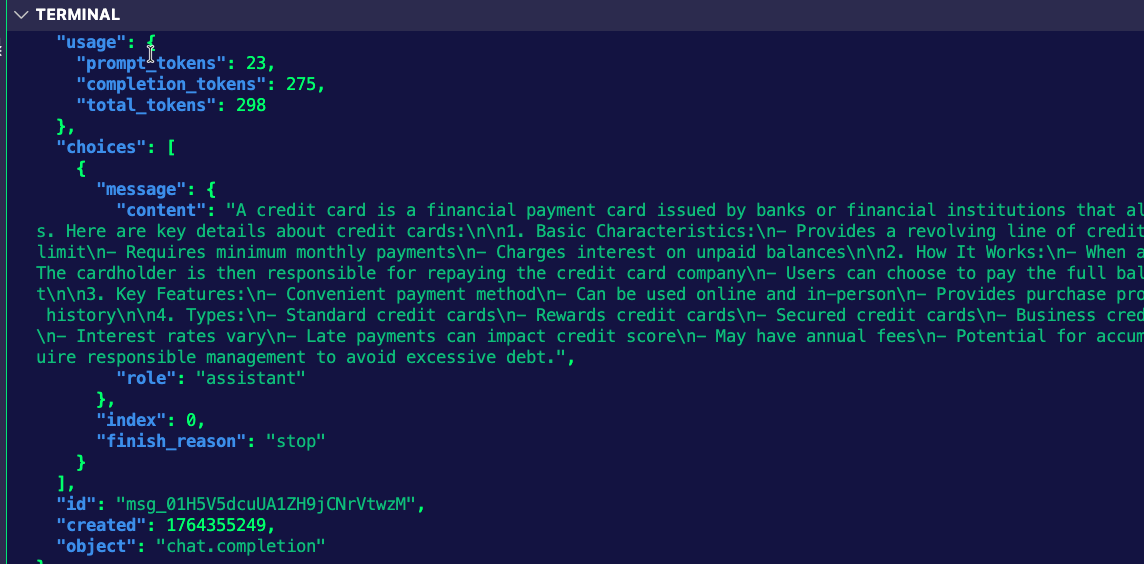
curl "$INGRESS_GW_ADDRESS:8080/anthropic" -H content-type:application/json -H x-api-key:$ANTHROPIC_API_KEY -H "anthropic-version: 2023-06-01" -d '{
"messages": [
{
"role": "system",
"content": "You are a skilled cloud-native network engineer."
},
{
"role": "user",
"content": "What is a credit card?"
}
]
}' | jqYou'll see an output similar to the below:
Creating A Prompt Guard
In the previous section, you were able to send a curl to the LLM to ask about credit card information, but what if that's a big no-no? As in, you don't want to do anything credit card related with your LLM?
Using a Prompt Guard, you can block that kind of prompt.
- Create an agentgateway policy that specifies the target reference as your HTTP Route and a regex that contains anything with the phrase "credit card".
kubectl apply -f - <<EOF
apiVersion: gateway.kgateway.dev/v1alpha1
kind: AgentgatewayPolicy
metadata:
name: credit-guard-prompt-guard
namespace: kgateway-system
labels:
app: agentgateway
spec:
targetRefs:
- group: gateway.networking.k8s.io
kind: HTTPRoute
name: claude
backend:
ai:
promptGuard:
request:
- response:
message: "Rejected due to inappropriate content"
regex:
action: REJECT
matches:
- "credit card"
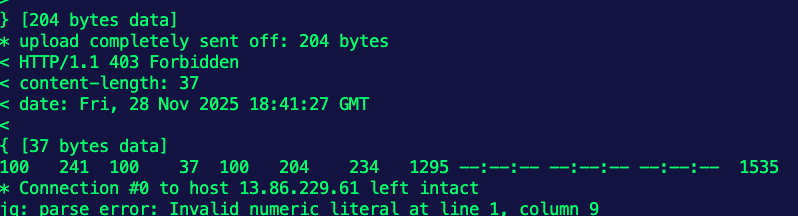
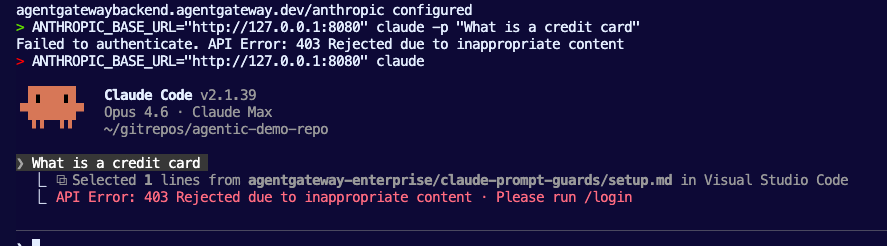
EOFTesting The Prompt Guard
- Try to run the
curlagain.
curl "$INGRESS_GW_ADDRESS:8080/anthropic" -v -H content-type:application/json -H x-api-key:$ANTHROPIC_API_KEY -H "anthropic-version: 2023-06-01" -d '{
"messages": [
{
"role": "system",
"content": "You are a skilled cloud-native network engineer."
},
{
"role": "user",
"content": "What is a credit card?"
}
]
}' | jqYou'll see an output similar to the below.
You can now set up any type of traffic policy you'd like to block prompts based on keyword or phrase.


Comments ()