Agent Harness: The SDLC Of Agentic Workflows
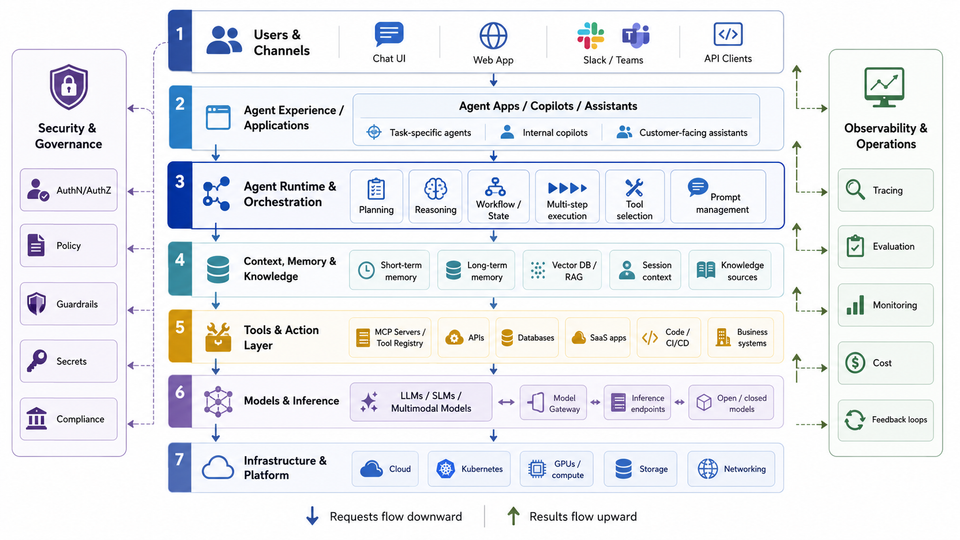
A Model is the “brains of the operation”, but what about everything else around it? Agents authenticating to Models, MCP Servers being exposed to all Agents without security, specialized information not being available, and zero out-of-the-box observability are just a few things that make up “everything else” outside of the brain.
That’s where Agent Harness comes into play.
This blog post will cover the stack you need for end-to-end AI.
Tldr; What’s Agent Harness?
An LLM takes in raw input and then outputs information. The “raw input” is text, audio, and images. LLMs provide the ability to utilize a “giant brain” filled with various pieces of information for anything and everything you can imagine. You ask for a thing, and it gives you a thing.
There are, however, several questions that come up after that realization:
- What about Agents?
- How is the traffic secured?
- Are the Agents isolated?
- Can Agent Skills, tools, and prompts be stored?
- What about Shadow AI?
- How can you test and confirm that an Agent performed the action effectively?
- What about logs, traces, and metrics?
Turns out, there’s a lot to implementing agentic workflows and that’s why Agent Harness exists. It’s the SDLC of Agentic.
Everything outside of the LLM is the harness. It’s the tools/products put together that encompass an agentic environment.
Agent Runtime
To interact with an LLM, the original approach was to have a chatbot of sorts (that’s how ChatGPT originated). If you have simple questions or want to use it like Google Search, that makes sense. If you want something that acts (like what an Agent does), the chatbot approach won’t work and an agent runtime is used.
Once an agent runtime is implemented, the agent needs to be secured, observed, and managed just like any other “system”. People are interacting with agents, agents are interacting with LLMs and MCP Servers, and they can cause real harm if not managed properly. Another key aspect of managing Agents is around long-term and short-term memory for context. If an Agent goes down for whatever reason, it needs to be able to access persistent memory.
Kagent = planning/tasks at the agent level, consisting of an LLM to call, tools to implement, and Agent Skills for expert knowledge.
Agent/AI Gateway
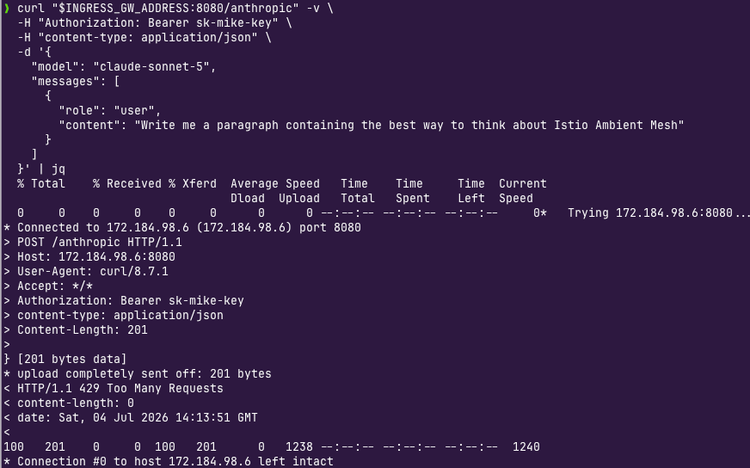
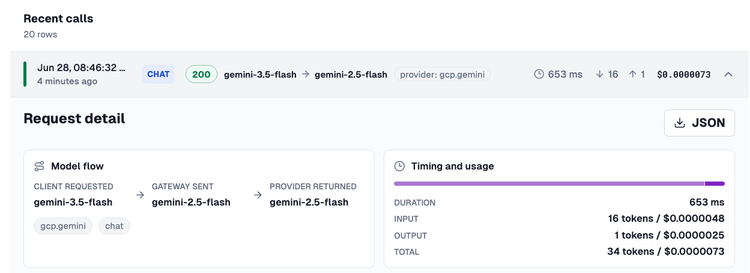
An Agent needs to get to its destination, which is typically an LLM, MCP Server, or another Agent. The question is “how can it do that?”. By default, the Agent is going over the public internet. That means you have no way to collect observability data for the Agents use, secure the call from the Agent to its destination, or run any tests to see how the Agent performed. That’s why all of the traffic needs to go through what I like to call a “secure line of communication”. This is where you can implement everything from OBO to trace/metric/log collectors to the ability to lock down MCP Server tools, manage inference, and overall traffic management.
Your AI Gateway is the make-or-break between what an Agent can do and what it will break.
Agentgateway = the secure tunnel of communication between your Agent and an LLM, MCP Server, or other Agent. It gives you the security implementations you need and observability data exposed for logs, traces, and metrics.
Shadow AI, Orchestration, and Registry
With Agents deployed using their MCP Server tools of choice, system messages/prompts, and Agent Skills to ensure that they have the exact expert information they need, the next two questions are:
- How do we give Prompts/Skills/Tools their own version of “source control”?
- Do we even know what Agents are running and where?
A recent Reddit post shows that number 2, Shadow AI, is on the rise and there’s zero chance that it will be solved by itself. Having the ability to not only ensure that your Agents have the components they need to succeed in a registry, but ensuring that those Agents can be discovered and managed once they’re deployed is key. Think about how big of a problem this is going to be as organizations implement more Agents and autonomous Agents become more popular. It’s going to be a technical debt and auditing nightmare.
Agentregistry = discover Agents deployed to reduce Shadow AI, give your Agent Skills/Tools/Prompts a place to live, and deploy said Skills/Tools/Prompts to Vertex, Bedrock, Foundry, or kagent.
Evaluations
Agents are deployed and they’re performing actions either autonomously or based on what a user asked them to do. These Agents can be running on a user's machine (think opencode, Claude Code, Codex, etc.) or on an agent runtime hosted in a production environment (e.g - kagent). As the industry has seen time and time again in countless posts, Agents and the client interacting with LLMs (e.g, all of the Claude Code issues in March/April) may not perform as well as expected. Having end-to-end tests to ensure that an Agent performs as expected for everything from “did the Agent hallucinate?” to “how was inference during this Agent call?” is important for anyone using AI for production. If you’re using autonomous agents as an SRE Agent or a SOC Agent, you want to ensure that the Agent is performing as well as expected. If the Agent is running locally for an engineer that’s building out a new feature or fixing a bug, the Agent has to perform in a way that it won’t introduce regressions.
Agentevals = end-to-end testing of how well your Agents performed.
Isolated Agents
Wherever an Agent runs, it has access to either what you have access to or what the Agents service account has access to. If an Agent is running locally on your behalf, that means it has access to whatever systems/cloud providers you have access to. If you can delete Kubernetes clusters, the Agent can delete Kubernetes clusters. If you can see all files/folders in a server, the Agent can. If you can run Azure CLI, AWS, or GCP commands to do anything from delete/deploy/modify cloud resources, the Agent can.
That’s why having the ability to isolate Agentic calls for anything from LLM calls to what it can actually access in the operating system makes the most sense.
kagent + NemoClaw + OpenShell = isolated agentic workloads (Agents themselves, calls to LLMs, etc.) that can have their own policies, procedures, and protocols for a fully encapsulated workflow.
Conclusion
As organizations begin to adopt AI more and more, two questions will emerge:
- How can I fit this into my current stack and workflows?
- What's the best way to implement a stack built specifically for Agentic workflows?
In other words, Agentic AI has gone from something interesting that organizations thought was cool to a need for implementing in production, and there needs to be a stack to ensure all organizations can do this effectively.

Comments ()